1-3,文本数据建模流程范例#
一,准备数据#
imdb数据集的目标是根据电影评论的文本内容预测评论的情感标签。
训练集有20000条电影评论文本,测试集有5000条电影评论文本,其中正面评论和负面评论都各占一半。
文本数据预处理较为繁琐,包括中文切词(本示例不涉及),构建词典,编码转换,序列填充,构建数据管道等等。
在torch中预处理文本数据一般使用torchtext或者自定义Dataset,torchtext功能非常强大,可以构建文本分类,序列标注,问答模型,机器翻译等NLP任务的数据集。
下面仅演示使用它来构建文本分类数据集的方法。
较完整的教程可以参考以下知乎文章:《pytorch学习笔记—Torchtext》
https://zhuanlan.zhihu.com/p/65833208

torchtext常见API一览
- torchtext.data.Example : 用来表示一个样本,数据和标签
- torchtext.vocab.Vocab: 词汇表,可以导入一些预训练词向量
- torchtext.data.Datasets: 数据集类,
__getitem__返回 Example实例, torchtext.data.TabularDataset是其子类。 - torchtext.data.Field : 用来定义字段的处理方法(文本字段,标签字段)创建 Example时的 预处理,batch 时的一些处理操作。
- torchtext.data.Iterator: 迭代器,用来生成 batch
- torchtext.datasets: 包含了常见的数据集.
import torch
import string,re
import torchtext
MAX_WORDS = 10000 # 仅考虑最高频的10000个词
MAX_LEN = 200 # 每个样本保留200个词的长度
BATCH_SIZE = 20
#分词方法
tokenizer = lambda x:re.sub('[%s]'%string.punctuation,"",x).split(" ")
#过滤掉低频词
def filterLowFreqWords(arr,vocab):
arr = [[x if x<MAX_WORDS else 0 for x in example]
for example in arr]
return arr
#1,定义各个字段的预处理方法
TEXT = torchtext.data.Field(sequential=True, tokenize=tokenizer, lower=True,
fix_length=MAX_LEN,postprocessing = filterLowFreqWords)
LABEL = torchtext.data.Field(sequential=False, use_vocab=False)
#2,构建表格型dataset
#torchtext.data.TabularDataset可读取csv,tsv,json等格式
ds_train, ds_test = torchtext.data.TabularDataset.splits(
path='../data/imdb', train='train.tsv',test='test.tsv', format='tsv',
fields=[('label', LABEL), ('text', TEXT)],skip_header = False)
#3,构建词典
TEXT.build_vocab(ds_train)
#4,构建数据管道迭代器
train_iter, test_iter = torchtext.data.Iterator.splits(
(ds_train, ds_test), sort_within_batch=True,sort_key=lambda x: len(x.text),
batch_sizes=(BATCH_SIZE,BATCH_SIZE))
#查看example信息
print(ds_train[0].text)
print(ds_train[0].label)
['it', 'really', 'boggles', 'my', 'mind', 'when', 'someone', 'comes', 'across', 'a', 'movie', 'like', 'this', 'and', 'claims', 'it', 'to', 'be', 'one', 'of', 'the', 'worst', 'slasher', 'films', 'out', 'there', 'this', 'is', 'by', 'far', 'not', 'one', 'of', 'the', 'worst', 'out', 'there', 'still', 'not', 'a', 'good', 'movie', 'but', 'not', 'the', 'worst', 'nonetheless', 'go', 'see', 'something', 'like', 'death', 'nurse', 'or', 'blood', 'lake', 'and', 'then', 'come', 'back', 'to', 'me', 'and', 'tell', 'me', 'if', 'you', 'think', 'the', 'night', 'brings', 'charlie', 'is', 'the', 'worst', 'the', 'film', 'has', 'decent', 'camera', 'work', 'and', 'editing', 'which', 'is', 'way', 'more', 'than', 'i', 'can', 'say', 'for', 'many', 'more', 'extremely', 'obscure', 'slasher', 'filmsbr', 'br', 'the', 'film', 'doesnt', 'deliver', 'on', 'the', 'onscreen', 'deaths', 'theres', 'one', 'death', 'where', 'you', 'see', 'his', 'pruning', 'saw', 'rip', 'into', 'a', 'neck', 'but', 'all', 'other', 'deaths', 'are', 'hardly', 'interesting', 'but', 'the', 'lack', 'of', 'onscreen', 'graphic', 'violence', 'doesnt', 'mean', 'this', 'isnt', 'a', 'slasher', 'film', 'just', 'a', 'bad', 'onebr', 'br', 'the', 'film', 'was', 'obviously', 'intended', 'not', 'to', 'be', 'taken', 'too', 'seriously', 'the', 'film', 'came', 'in', 'at', 'the', 'end', 'of', 'the', 'second', 'slasher', 'cycle', 'so', 'it', 'certainly', 'was', 'a', 'reflection', 'on', 'traditional', 'slasher', 'elements', 'done', 'in', 'a', 'tongue', 'in', 'cheek', 'way', 'for', 'example', 'after', 'a', 'kill', 'charlie', 'goes', 'to', 'the', 'towns', 'welcome', 'sign', 'and', 'marks', 'the', 'population', 'down', 'one', 'less', 'this', 'is', 'something', 'that', 'can', 'only', 'get', 'a', 'laughbr', 'br', 'if', 'youre', 'into', 'slasher', 'films', 'definitely', 'give', 'this', 'film', 'a', 'watch', 'it', 'is', 'slightly', 'different', 'than', 'your', 'usual', 'slasher', 'film', 'with', 'possibility', 'of', 'two', 'killers', 'but', 'not', 'by', 'much', 'the', 'comedy', 'of', 'the', 'movie', 'is', 'pretty', 'much', 'telling', 'the', 'audience', 'to', 'relax', 'and', 'not', 'take', 'the', 'movie', 'so', 'god', 'darn', 'serious', 'you', 'may', 'forget', 'the', 'movie', 'you', 'may', 'remember', 'it', 'ill', 'remember', 'it', 'because', 'i', 'love', 'the', 'name']
0
# 查看词典信息
print(len(TEXT.vocab))
#itos: index to string
print(TEXT.vocab.itos[0])
print(TEXT.vocab.itos[1])
#stoi: string to index
print(TEXT.vocab.stoi['<unk>']) #unknown 未知词
print(TEXT.vocab.stoi['<pad>']) #padding 填充
#freqs: 词频
print(TEXT.vocab.freqs['<unk>'])
print(TEXT.vocab.freqs['a'])
print(TEXT.vocab.freqs['good'])
108197
<unk>
<pad>
0
1
0
129453
11457
# 查看数据管道信息
# 注意有坑:text第0维是句子长度
for batch in train_iter:
features = batch.text
labels = batch.label
print(features)
print(features.shape)
print(labels)
break
tensor([[ 17, 31, 148, ..., 54, 11, 201],
[ 2, 2, 904, ..., 335, 7, 109],
[1371, 1737, 44, ..., 806, 2, 11],
...,
[ 6, 5, 62, ..., 1, 1, 1],
[ 170, 0, 27, ..., 1, 1, 1],
[ 15, 0, 45, ..., 1, 1, 1]])
torch.Size([200, 20])
tensor([0, 1, 0, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 0, 0])
# 将数据管道组织成torch.utils.data.DataLoader相似的features,label输出形式
class DataLoader:
def __init__(self,data_iter):
self.data_iter = data_iter
self.length = len(data_iter)
def __len__(self):
return self.length
def __iter__(self):
# 注意:此处调整features为 batch first,并调整label的shape和dtype
for batch in self.data_iter:
yield(torch.transpose(batch.text,0,1),
torch.unsqueeze(batch.label.float(),dim = 1))
dl_train = DataLoader(train_iter)
dl_test = DataLoader(test_iter)
二,定义模型#
使用Pytorch通常有三种方式构建模型:使用nn.Sequential按层顺序构建模型,继承nn.Module基类构建自定义模型,继承nn.Module基类构建模型并辅助应用模型容器(nn.Sequential,nn.ModuleList,nn.ModuleDict)进行封装。
此处选择使用第三种方式进行构建。
由于接下来使用类形式的训练循环,我们将模型封装成torchkeras.Model类来获得类似Keras中高阶模型接口的功能。
Model类实际上继承自nn.Module类。
import torch
from torch import nn
import torchkeras
torch.random.seed()
import torch
from torch import nn
class Net(torchkeras.Model):
def __init__(self):
super(Net, self).__init__()
#设置padding_idx参数后将在训练过程中将填充的token始终赋值为0向量
self.embedding = nn.Embedding(num_embeddings = MAX_WORDS,embedding_dim = 3,padding_idx = 1)
self.conv = nn.Sequential()
self.conv.add_module("conv_1",nn.Conv1d(in_channels = 3,out_channels = 16,kernel_size = 5))
self.conv.add_module("pool_1",nn.MaxPool1d(kernel_size = 2))
self.conv.add_module("relu_1",nn.ReLU())
self.conv.add_module("conv_2",nn.Conv1d(in_channels = 16,out_channels = 128,kernel_size = 2))
self.conv.add_module("pool_2",nn.MaxPool1d(kernel_size = 2))
self.conv.add_module("relu_2",nn.ReLU())
self.dense = nn.Sequential()
self.dense.add_module("flatten",nn.Flatten())
self.dense.add_module("linear",nn.Linear(6144,1))
self.dense.add_module("sigmoid",nn.Sigmoid())
def forward(self,x):
x = self.embedding(x).transpose(1,2)
x = self.conv(x)
y = self.dense(x)
return y
model = Net()
print(model)
model.summary(input_shape = (200,),input_dtype = torch.LongTensor)
Net(
(embedding): Embedding(10000, 3, padding_idx=1)
(conv): Sequential(
(conv_1): Conv1d(3, 16, kernel_size=(5,), stride=(1,))
(pool_1): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(relu_1): ReLU()
(conv_2): Conv1d(16, 128, kernel_size=(2,), stride=(1,))
(pool_2): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(relu_2): ReLU()
)
(dense): Sequential(
(flatten): Flatten()
(linear): Linear(in_features=6144, out_features=1, bias=True)
(sigmoid): Sigmoid()
)
)
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Embedding-1 [-1, 200, 3] 30,000
Conv1d-2 [-1, 16, 196] 256
MaxPool1d-3 [-1, 16, 98] 0
ReLU-4 [-1, 16, 98] 0
Conv1d-5 [-1, 128, 97] 4,224
MaxPool1d-6 [-1, 128, 48] 0
ReLU-7 [-1, 128, 48] 0
Flatten-8 [-1, 6144] 0
Linear-9 [-1, 1] 6,145
Sigmoid-10 [-1, 1] 0
================================================================
Total params: 40,625
Trainable params: 40,625
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.000763
Forward/backward pass size (MB): 0.287796
Params size (MB): 0.154972
Estimated Total Size (MB): 0.443531
----------------------------------------------------------------
三,训练模型#
训练Pytorch通常需要用户编写自定义训练循环,训练循环的代码风格因人而异。
有3类典型的训练循环代码风格:脚本形式训练循环,函数形式训练循环,类形式训练循环。
此处介绍一种类形式的训练循环。
我们仿照Keras定义了一个高阶的模型接口Model,实现 fit, validate,predict, summary 方法,相当于用户自定义高阶API。
# 准确率
def accuracy(y_pred,y_true):
y_pred = torch.where(y_pred>0.5,torch.ones_like(y_pred,dtype = torch.float32),
torch.zeros_like(y_pred,dtype = torch.float32))
acc = torch.mean(1-torch.abs(y_true-y_pred))
return acc
model.compile(loss_func = nn.BCELoss(),optimizer= torch.optim.Adagrad(model.parameters(),lr = 0.02),
metrics_dict={"accuracy":accuracy})
# 有时候模型训练过程中不收敛,需要多试几次
dfhistory = model.fit(20,dl_train,dl_val=dl_test,log_step_freq= 200)
Start Training ...
================================================================================2020-05-09 17:53:56
{'step': 200, 'loss': 1.127, 'accuracy': 0.504}
{'step': 400, 'loss': 0.908, 'accuracy': 0.517}
{'step': 600, 'loss': 0.833, 'accuracy': 0.531}
{'step': 800, 'loss': 0.793, 'accuracy': 0.545}
{'step': 1000, 'loss': 0.765, 'accuracy': 0.56}
+-------+-------+----------+----------+--------------+
| epoch | loss | accuracy | val_loss | val_accuracy |
+-------+-------+----------+----------+--------------+
| 1 | 0.765 | 0.56 | 0.64 | 0.64 |
+-------+-------+----------+----------+--------------+
================================================================================2020-05-09 17:54:23
{'step': 200, 'loss': 0.626, 'accuracy': 0.659}
{'step': 400, 'loss': 0.621, 'accuracy': 0.662}
{'step': 600, 'loss': 0.616, 'accuracy': 0.664}
{'step': 800, 'loss': 0.61, 'accuracy': 0.671}
{'step': 1000, 'loss': 0.603, 'accuracy': 0.677}
+-------+-------+----------+----------+--------------+
| epoch | loss | accuracy | val_loss | val_accuracy |
+-------+-------+----------+----------+--------------+
| 2 | 0.603 | 0.677 | 0.577 | 0.705 |
+-------+-------+----------+----------+--------------+
================================================================================2020-05-09 17:54:50
{'step': 200, 'loss': 0.545, 'accuracy': 0.726}
{'step': 400, 'loss': 0.538, 'accuracy': 0.735}
{'step': 600, 'loss': 0.532, 'accuracy': 0.737}
{'step': 800, 'loss': 0.531, 'accuracy': 0.737}
{'step': 1000, 'loss': 0.528, 'accuracy': 0.739}
+-------+-------+----------+----------+--------------+
| epoch | loss | accuracy | val_loss | val_accuracy |
+-------+-------+----------+----------+--------------+
| 3 | 0.528 | 0.739 | 0.536 | 0.739 |
+-------+-------+----------+----------+--------------+
================================================================================2020-05-09 17:55:18
{'step': 200, 'loss': 0.488, 'accuracy': 0.773}
{'step': 400, 'loss': 0.482, 'accuracy': 0.774}
{'step': 600, 'loss': 0.482, 'accuracy': 0.773}
{'step': 800, 'loss': 0.479, 'accuracy': 0.773}
{'step': 1000, 'loss': 0.473, 'accuracy': 0.776}
+-------+-------+----------+----------+--------------+
| epoch | loss | accuracy | val_loss | val_accuracy |
+-------+-------+----------+----------+--------------+
| 4 | 0.473 | 0.776 | 0.504 | 0.766 |
+-------+-------+----------+----------+--------------+
================================================================================2020-05-09 17:55:45
{'step': 200, 'loss': 0.446, 'accuracy': 0.789}
{'step': 400, 'loss': 0.437, 'accuracy': 0.796}
{'step': 600, 'loss': 0.436, 'accuracy': 0.799}
{'step': 800, 'loss': 0.436, 'accuracy': 0.798}
{'step': 1000, 'loss': 0.434, 'accuracy': 0.8}
+-------+-------+----------+----------+--------------+
| epoch | loss | accuracy | val_loss | val_accuracy |
+-------+-------+----------+----------+--------------+
| 5 | 0.434 | 0.8 | 0.481 | 0.774 |
+-------+-------+----------+----------+--------------+
================================================================================2020-05-09 17:56:12
{'step': 200, 'loss': 0.404, 'accuracy': 0.817}
{'step': 400, 'loss': 0.4, 'accuracy': 0.819}
{'step': 600, 'loss': 0.398, 'accuracy': 0.821}
{'step': 800, 'loss': 0.402, 'accuracy': 0.818}
{'step': 1000, 'loss': 0.402, 'accuracy': 0.817}
+-------+-------+----------+----------+--------------+
| epoch | loss | accuracy | val_loss | val_accuracy |
+-------+-------+----------+----------+--------------+
| 6 | 0.402 | 0.817 | 0.47 | 0.781 |
+-------+-------+----------+----------+--------------+
================================================================================2020-05-09 17:56:39
{'step': 200, 'loss': 0.369, 'accuracy': 0.834}
{'step': 400, 'loss': 0.374, 'accuracy': 0.833}
{'step': 600, 'loss': 0.373, 'accuracy': 0.834}
{'step': 800, 'loss': 0.374, 'accuracy': 0.834}
{'step': 1000, 'loss': 0.375, 'accuracy': 0.833}
+-------+-------+----------+----------+--------------+
| epoch | loss | accuracy | val_loss | val_accuracy |
+-------+-------+----------+----------+--------------+
| 7 | 0.375 | 0.833 | 0.468 | 0.787 |
+-------+-------+----------+----------+--------------+
================================================================================2020-05-09 17:57:06
{'step': 200, 'loss': 0.36, 'accuracy': 0.839}
{'step': 400, 'loss': 0.355, 'accuracy': 0.846}
{'step': 600, 'loss': 0.35, 'accuracy': 0.849}
{'step': 800, 'loss': 0.353, 'accuracy': 0.846}
{'step': 1000, 'loss': 0.352, 'accuracy': 0.847}
+-------+-------+----------+----------+--------------+
| epoch | loss | accuracy | val_loss | val_accuracy |
+-------+-------+----------+----------+--------------+
| 8 | 0.352 | 0.847 | 0.461 | 0.791 |
+-------+-------+----------+----------+--------------+
================================================================================2020-05-09 17:57:33
{'step': 200, 'loss': 0.313, 'accuracy': 0.867}
{'step': 400, 'loss': 0.326, 'accuracy': 0.862}
{'step': 600, 'loss': 0.331, 'accuracy': 0.86}
{'step': 800, 'loss': 0.333, 'accuracy': 0.859}
{'step': 1000, 'loss': 0.332, 'accuracy': 0.859}
+-------+-------+----------+----------+--------------+
| epoch | loss | accuracy | val_loss | val_accuracy |
+-------+-------+----------+----------+--------------+
| 9 | 0.332 | 0.859 | 0.462 | 0.789 |
+-------+-------+----------+----------+--------------+
================================================================================2020-05-09 17:58:00
{'step': 200, 'loss': 0.309, 'accuracy': 0.869}
{'step': 400, 'loss': 0.31, 'accuracy': 0.872}
{'step': 600, 'loss': 0.31, 'accuracy': 0.871}
{'step': 800, 'loss': 0.311, 'accuracy': 0.869}
{'step': 1000, 'loss': 0.314, 'accuracy': 0.869}
+-------+-------+----------+----------+--------------+
| epoch | loss | accuracy | val_loss | val_accuracy |
+-------+-------+----------+----------+--------------+
| 10 | 0.314 | 0.869 | 0.46 | 0.793 |
+-------+-------+----------+----------+--------------+
================================================================================2020-05-09 17:58:26
{'step': 200, 'loss': 0.3, 'accuracy': 0.88}
{'step': 400, 'loss': 0.293, 'accuracy': 0.881}
{'step': 600, 'loss': 0.297, 'accuracy': 0.878}
{'step': 800, 'loss': 0.299, 'accuracy': 0.877}
{'step': 1000, 'loss': 0.297, 'accuracy': 0.878}
+-------+-------+----------+----------+--------------+
| epoch | loss | accuracy | val_loss | val_accuracy |
+-------+-------+----------+----------+--------------+
| 11 | 0.297 | 0.878 | 0.471 | 0.789 |
+-------+-------+----------+----------+--------------+
================================================================================2020-05-09 17:58:54
{'step': 200, 'loss': 0.275, 'accuracy': 0.891}
{'step': 400, 'loss': 0.282, 'accuracy': 0.887}
{'step': 600, 'loss': 0.283, 'accuracy': 0.888}
{'step': 800, 'loss': 0.283, 'accuracy': 0.887}
{'step': 1000, 'loss': 0.282, 'accuracy': 0.886}
+-------+-------+----------+----------+--------------+
| epoch | loss | accuracy | val_loss | val_accuracy |
+-------+-------+----------+----------+--------------+
| 12 | 0.282 | 0.886 | 0.465 | 0.795 |
+-------+-------+----------+----------+--------------+
================================================================================2020-05-09 17:59:22
{'step': 200, 'loss': 0.26, 'accuracy': 0.903}
{'step': 400, 'loss': 0.268, 'accuracy': 0.894}
{'step': 600, 'loss': 0.271, 'accuracy': 0.893}
{'step': 800, 'loss': 0.267, 'accuracy': 0.893}
{'step': 1000, 'loss': 0.268, 'accuracy': 0.892}
+-------+-------+----------+----------+--------------+
| epoch | loss | accuracy | val_loss | val_accuracy |
+-------+-------+----------+----------+--------------+
| 13 | 0.268 | 0.892 | 0.472 | 0.794 |
+-------+-------+----------+----------+--------------+
================================================================================2020-05-09 17:59:49
{'step': 200, 'loss': 0.252, 'accuracy': 0.903}
{'step': 400, 'loss': 0.25, 'accuracy': 0.905}
{'step': 600, 'loss': 0.251, 'accuracy': 0.903}
{'step': 800, 'loss': 0.253, 'accuracy': 0.9}
{'step': 1000, 'loss': 0.255, 'accuracy': 0.9}
+-------+-------+----------+----------+--------------+
| epoch | loss | accuracy | val_loss | val_accuracy |
+-------+-------+----------+----------+--------------+
| 14 | 0.255 | 0.9 | 0.469 | 0.796 |
+-------+-------+----------+----------+--------------+
================================================================================2020-05-09 18:00:16
{'step': 200, 'loss': 0.242, 'accuracy': 0.912}
{'step': 400, 'loss': 0.237, 'accuracy': 0.911}
{'step': 600, 'loss': 0.24, 'accuracy': 0.91}
{'step': 800, 'loss': 0.241, 'accuracy': 0.908}
{'step': 1000, 'loss': 0.242, 'accuracy': 0.906}
+-------+-------+----------+----------+--------------+
| epoch | loss | accuracy | val_loss | val_accuracy |
+-------+-------+----------+----------+--------------+
| 15 | 0.242 | 0.906 | 0.475 | 0.797 |
+-------+-------+----------+----------+--------------+
================================================================================2020-05-09 18:00:44
{'step': 200, 'loss': 0.218, 'accuracy': 0.921}
{'step': 400, 'loss': 0.223, 'accuracy': 0.916}
{'step': 600, 'loss': 0.229, 'accuracy': 0.912}
{'step': 800, 'loss': 0.229, 'accuracy': 0.913}
{'step': 1000, 'loss': 0.231, 'accuracy': 0.911}
+-------+-------+----------+----------+--------------+
| epoch | loss | accuracy | val_loss | val_accuracy |
+-------+-------+----------+----------+--------------+
| 16 | 0.231 | 0.911 | 0.486 | 0.794 |
+-------+-------+----------+----------+--------------+
================================================================================2020-05-09 18:01:12
{'step': 200, 'loss': 0.21, 'accuracy': 0.919}
{'step': 400, 'loss': 0.22, 'accuracy': 0.915}
{'step': 600, 'loss': 0.22, 'accuracy': 0.915}
{'step': 800, 'loss': 0.22, 'accuracy': 0.916}
{'step': 1000, 'loss': 0.22, 'accuracy': 0.916}
+-------+------+----------+----------+--------------+
| epoch | loss | accuracy | val_loss | val_accuracy |
+-------+------+----------+----------+--------------+
| 17 | 0.22 | 0.916 | 0.486 | 0.796 |
+-------+------+----------+----------+--------------+
================================================================================2020-05-09 18:02:24
{'step': 200, 'loss': 0.206, 'accuracy': 0.927}
{'step': 400, 'loss': 0.21, 'accuracy': 0.923}
{'step': 600, 'loss': 0.21, 'accuracy': 0.924}
{'step': 800, 'loss': 0.213, 'accuracy': 0.922}
{'step': 1000, 'loss': 0.21, 'accuracy': 0.923}
+-------+------+----------+----------+--------------+
| epoch | loss | accuracy | val_loss | val_accuracy |
+-------+------+----------+----------+--------------+
| 18 | 0.21 | 0.923 | 0.493 | 0.796 |
+-------+------+----------+----------+--------------+
================================================================================2020-05-09 18:02:53
{'step': 200, 'loss': 0.191, 'accuracy': 0.932}
{'step': 400, 'loss': 0.197, 'accuracy': 0.926}
{'step': 600, 'loss': 0.199, 'accuracy': 0.928}
{'step': 800, 'loss': 0.199, 'accuracy': 0.927}
{'step': 1000, 'loss': 0.2, 'accuracy': 0.927}
+-------+------+----------+----------+--------------+
| epoch | loss | accuracy | val_loss | val_accuracy |
+-------+------+----------+----------+--------------+
| 19 | 0.2 | 0.927 | 0.5 | 0.794 |
+-------+------+----------+----------+--------------+
================================================================================2020-05-09 18:03:22
{'step': 200, 'loss': 0.19, 'accuracy': 0.934}
{'step': 400, 'loss': 0.192, 'accuracy': 0.931}
{'step': 600, 'loss': 0.195, 'accuracy': 0.929}
{'step': 800, 'loss': 0.194, 'accuracy': 0.93}
{'step': 1000, 'loss': 0.191, 'accuracy': 0.931}
+-------+-------+----------+----------+--------------+
| epoch | loss | accuracy | val_loss | val_accuracy |
+-------+-------+----------+----------+--------------+
| 20 | 0.191 | 0.931 | 0.506 | 0.795 |
+-------+-------+----------+----------+--------------+
================================================================================2020-05-09 18:03:58
Finished Training...
四,评估模型#
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
import matplotlib.pyplot as plt
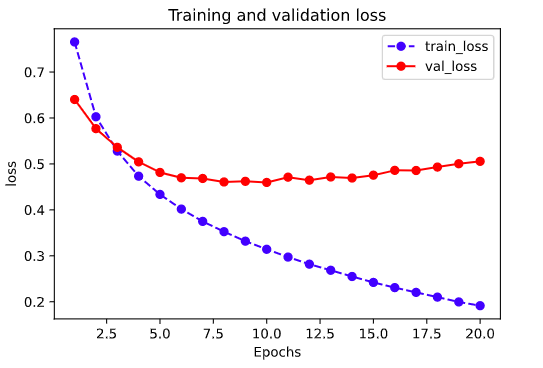
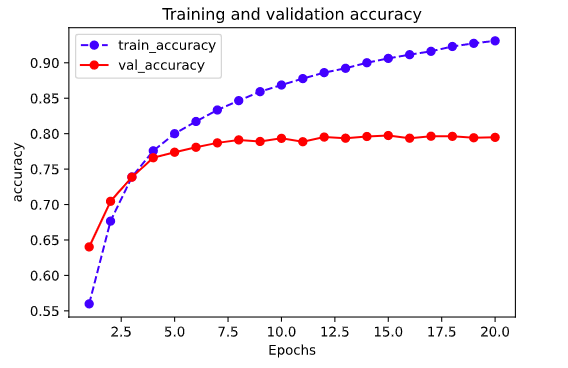
def plot_metric(dfhistory, metric):
train_metrics = dfhistory[metric]
val_metrics = dfhistory['val_'+metric]
epochs = range(1, len(train_metrics) + 1)
plt.plot(epochs, train_metrics, 'bo--')
plt.plot(epochs, val_metrics, 'ro-')
plt.title('Training and validation '+ metric)
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend(["train_"+metric, 'val_'+metric])
plt.show()
plot_metric(dfhistory,"loss")
plot_metric(dfhistory,"accuracy")
# 评估
model.evaluate(dl_test)
{'val_loss': 0.5056138457655907, 'val_accuracy': 0.7948000040054322}
五,使用模型#
model.predict(dl_test)
tensor([[3.9803e-02],
[9.9295e-01],
[6.0493e-01],
...,
[1.2023e-01],
[9.3701e-01],
[2.5752e-04]])
六,保存模型#
推荐使用保存参数方式保存Pytorch模型。
print(model.state_dict().keys())
odict_keys(['embedding.weight', 'conv.conv_1.weight', 'conv.conv_1.bias', 'conv.conv_2.weight', 'conv.conv_2.bias', 'dense.linear.weight', 'dense.linear.bias'])
# 保存模型参数
torch.save(model.state_dict(), "../data/model_parameter.pkl")
model_clone = Net()
model_clone.load_state_dict(torch.load("../data/model_parameter.pkl"))
model_clone.compile(loss_func = nn.BCELoss(),optimizer= torch.optim.Adagrad(model.parameters(),lr = 0.02),
metrics_dict={"accuracy":accuracy})
# 评估模型
model_clone.evaluate(dl_test)
{'val_loss': 0.5056138457655907, 'val_accuracy': 0.7948000040054322}
如果对本书内容理解上有需要进一步和作者交流的地方,欢迎在公众号"Python与算法之美"下留言。作者时间和精力有限,会酌情予以回复。
也可以在公众号后台回复关键字:加群,加入读者交流群和大家讨论。
